Téma web scrapera sa na tomto blogu vyskytla v roku 2018. Toho času riešila problematiku, ako si vytvoriť jednoduchý web scraper na platforme ESP8266 / ESP32. Tá konkrétna implementácia web scrapera využívala ESP v klientskom móde, pričom využívala dva nezávislé spojenia na dva webservery. Implementácia využívala pre jedno spojenie websocket a pre druhé HTTPClient.
Websocket načítaval webovú stránku po riadkoch zdrojového kódu a posielal ju na druhý webserver prostredníctvom HTTPClienta. Webserver, ktorý riadok webovej stránky prijal dokázal na základe regulárneho výrazu vyprasovať jeho obsah a v prípade e-mailovej adresy, alebo telefónneho čísla tento údaj uložiť do MySQL databázy a dynamicky tak rozšíriť už existujúcu databázu takýchto údajov.
Plnohodnotný web scraper by však mal bežať na jednom zariadení a nemal by byť závislý od iných systémov, čo komplikuje jeho správu a možnosti jeho ovládania. Z toho dôvodu som sa dnes rozhodol rozšíriť túto tému pre plnohodnotný client-side webscraper na platforme Arduino s Ethernet shieldom a WiFi platformami ESP8266, ESP32. Web scraper má výlučne edukatívny charakter pre tento článok.
Získané informácie neboli uložené, boli získané iba jednorázovo za účelom demonštrovania funkcie webscrapera v článku s použitím websocketu ako pri využití webovej stránky akýmkoľvek prehliadačom prostredníctvom človeka. S dátami bolo naložené eticky bez publikácie načítaného obsahu na iných webových stránkach. Dáta boli obsiahnuté iba v RAM pamäti mikrokontrolérov pre účely výpisu z buffra.
Prvým krokom pri implementácii web scrapera na takejto embeeded platforme musí byť analýza konkrétnej webovej stránky, z ktorej chceme získať údaje. Súčasťou analýzy je aj nájsť si vodítka, ktoré môžu zjednodušiť celý proces web scrapingu.
Ak načítavame dynamický údaj z webovej stránky, môžeme predpokladať, kde sa bude nachádzať v štruktúre načítaného HTML zdrojové kódu webstránky, napríklad medzi párovým td..../td HTML tagom, prípadne pre lepšiu špecifikáciu môzeme hľadať informáciu detailnejšie aj na základe class, identifikátorov a iných atribútov, ktoré môžu HTML elementy nadobúdať. To však treba mať na pamäti aj to, že musíme načítavať zdrojový kód v rozmedzí týchto tagov a nie po riadkoch, nakoľko štruktúra html môže mať v samostatných riadkoch tagy a aj informáciu.
Prípadne ak sa jedná o jednoduchú statickú informáciu (telefónne číslo), môžeme ju načítať regulárnym výrazom pri prechádzaní stránky po riadkoch jednotlivo, nakoľko najčastejšie bude mať mobilné telefónne číslo formu a môžeme predpokladať, že sa nachádza v jednom riadku:
- +421 900 000 000
- +421900000000
- +421 900 00 00 00
- 0900 000 000
- 0900000000
- 0 900 00 00 00
Ukážme si však príklad, ako ku web scrapingu na spomenutých platformách Arduino, ESP8266, ESP32.
1. Scraping internetovej diskusie
Pozrime sa do internetovej diskusie k istému seriálu a prezrime si jeden z komentárov a následne aj zdrojový kód HTML stránky v týchto miestach.


Z analýzy zdrojového kódu je zremé, že celý komentár je obalený v kontajneri div s classou item. Následne v jednotlivých spanoch s classami: name, date, title a message sú obsiahnuté informácie: meno, dátum s časom, titulok (nadpis) a správa. Na základe jednotlivých spanov sme schopní vyparsovať danú informáciu. Takto dokážeme získať zo stránky všetky údaje, ktoré sa na nej vyskytujú, keďže vieme medzi ktorými HTML elementami sú.
2. Scraping inzertného portálu
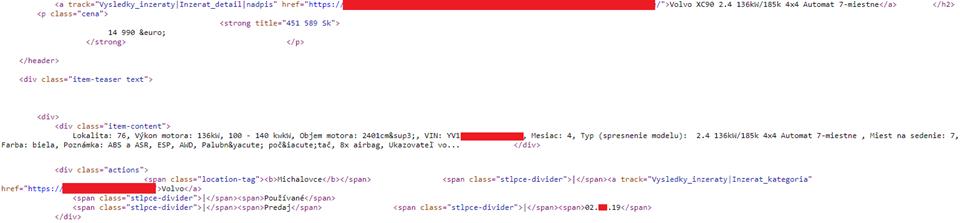
Inzertné portály sú jedny z najjednoduchších pre web scraping. Predstavme si modelovú situáciu vyhľadávania, pričom hľadáme inzeráty v kategórii Nákladné autá. Okrem údajov z titulku inzerátu vo vyhľadávaní môžeme získať aj rôzne doplnkové - inak priamo nie viditeľné informácie a to link na celý inzerát, ktorý môžeme následne použiť aj pre scraping tela inzerátu, ktorým môžeme získať ďalšie zaujímavé informácie - telefónne číslo, meno inzertera, rok výroby vozidla, počet najazdených kilometrov.

Z analýzy zdrojového kódu sme zistili aj ďalšie zaujímavé informácie. Vidíme priamy link na telo inzerátu, ktorý je možné využiť pre crawling, cenu vozidla v slovenských korunách, ktorá je prepočítaná na eurá. Ďalej je možné zistiť všetky informácie (kategória, stav, ponúka/kúpa, dátum). Všimnite si zaujímavosť v podobe bezpečných HTML znakov vo vnútri HTML elementov, ktoré vyžadujú dodatočné pretvorenie znakov na čitateľnú podobu, napríklad €.

Spomenuté platformy Arduino, ESP8266, ESP32 dokážu vykonať aj špecifický GET / POST request na HTTP / HTTPS (na HTTPS iba platformy ESP8266 a ESP32). To umožňuje spustiť napríklad HTML formulár s potrebným vstupom, čo môže na základe konkrétnej stránky filtrovať výstup stránky (kľúčové slovo na inzerných a vyhľadávacích portáloch), prípadne na základe parametra dostaneme presný výsledok, ktorý predpokladáme a z dát, ktoré webová stránka vypíše môžeme následne parsovať.
Ukážeme si príklad scrapingu z POST HTTP requestu na stránku Ministerstva vnútra SR, kde je možné overiť kradnuté vozidlo na základe vstupu evidenčného čísla do HTML formulára.
Formulár obsahuje textový vstup, ktorý predstavuje evidenčné číslo vozidla.
input name="ec" id="ec" type="text"
Na základe requestu môžeme na cieľovú webovú stránku vykonať request, pričom do tela requestu obsiahneme aj parameter ec, ktorý spracuje formulár webovej stránky a ponúkne nám k nemu výpis (ak existuje daný záznam).
Pri vykonaní requestu webserver odpovie HTML stránkou, ktorá obsahuje informácie o zadanej podmienke. V prípade, že je pozitívny záznam, hodnota = 1, stránka vypíše aj ďalšie informácie o vozidle, ktoré môžeme scraperom spracovať. Medzi informáciami je možné nájsť označenie, model, farbu vozidla. Dátum a čas odcudzenia EVČ, jeho VIN číslo a podobne. Na hodnotu 1 zareaguje aj aplikácia bežiaca na mikrokontroléri, ktorá vypíše informáciu o vyhlásenom pátraní a o kontaktovaní polície.

V prípade, že sa pozitívny záznam nenájde, strának vypíše hodnotu = 0 bez ďalších informácii o vozidle. Web scaper využíval UART vstup (premenná my_datas), ktorý predstavoval hľadané evidenčné číslo vozidla. Okrem parametra ec (EVČ) dokáže daný formulár spracovať aj VIN číslo vozidla pod parametrom vin. Výstupovo je HTML stránka rovnaká s údajmi o vozidle v prípade pozitívneho výsledku na odcuzené vozidlo.
Pre websocket spojenie je možné použiť vstavané WiFiClient / EthernetClient príklady v prostredí Arduino IDE pre všetky spomenuté platformy. Web scraper by mal byť napísaný čo najefektívnejšie, čo sa týka využitie pamäte.
V mojich testovacích implementáciách som využil pre načítavanie classu String, ktorá je dynamická a prostredníctvom nej je možné načítať texty s variablinou dĺžkou. String je uložený do RAM pamäte. Nakoľko Arduino Uno má iba 2kB pamäte RAM, je nutné načítavať menšie dĺžky zdrojového kódu. ESP8266 má 96kB RAM, ESP32 vyše 500kB RAM. V RAM-kách beží aj aplikácia, ktorá zaberá isté percento pamäte.
Časť implementácie aplikácie web scrapera, ktorá na základe obsahu riadkov a terminátorov je schopná niečo vypísať na UART + prebrať informácie z webovej stránky - Druh, Značka, Model vozidla atď... Načítava sa jednotlivo po riadkoch t.j. po ukončovací znak riadka prípadne následujúce riadky v prípade, že sa informácia nachádzala o riadok nižšie v HTML kóde.

Projekt môže byť zaujímavý pre rozšírenie o modul ESP-CAM, ktorý obsahuje 2Mpix kameru, ktorú je možné použiť napríklad pre načítanie EVČ vozidla v reálnom čase (OCR) a requestom na stránku minv overiť, či je vozidlo kradnuté.
Nevýhody web scraperov postavených na platforme Arduino, ESP8266, ESP32:
- Web scrapery nedokážu vykonať autentizáciu cez Captcha zabezpečenie
- Scraper nespustí Javascript
- Scraper neuvidí dynamické dáta na stránke, ktoré vykoná Javascript (načíta iba dáta pri spustení stránky, t.j. jej zdrojový kód)
- Pomerne málo pamäte pre zložitejšie a obsiahlejšie texty
Programová implementácia scrapera pre edukačné účely je dostupná na Githube:
https://github.com/martinius96/WebScraper-ESP



 PRIHLÁS SA
PRIHLÁS SA